[6] 구글 이미지 크롤러
전에 설명하였던 yolo를 통해 자신의 데이터를 학습 시키기 위해 데이터 세트를 수집하는 방법에 대해 설명드리겠습니다.
저와 같은 경우 구글에 이미지 검색을 통해 나오는 이미지를 학습에 사용하였습니다.
구글의 이미지를 크롤링 하는 방법은 두가지 방법을 사용하여봤습니다.
1. python 코드를 통한 이미지 크롤링
우선 이미지를 크롤링 하기위해선 chrome을 사용시 chromedriver를 설치해주셔야됩니다.
Chrome : https://sites.google.com/a/chromium.org/chromedriver/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
sites.google.com
설치를 완료하셨다면 selenium을 설치해줍니다.
$ pip install selenium
설치를 완료하셨다음 다음과 같은 코드를 이용해 크롤링을 해줍니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import json
import os
import urllib2
import argparse
searchterm = 'pothole' # will also be the name of the folder
url = "https://www.google.co.in/search?q="+searchterm+"&source=lnms&tbm=isch"
# NEED TO DOWNLOAD CHROMEDRIVER, insert path to chromedriver inside parentheses in following line
browser = webdriver.Chrome('/Users/sungjin/Desktop/univ/capstone/chromedriver')
browser.get(url)
header={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36"}
counter = 0
succounter = 0
if not os.path.exists(searchterm):
os.mkdir(searchterm)
for _ in range(500):
browser.execute_script("window.scrollBy(0,10000)")
for x in browser.find_elements_by_xpath('//div[contains(@class,"rg_meta")]'):
counter = counter + 1
print "Total Count:", counter
print "Succsessful Count:", succounter
print "URL:",json.loads(x.get_attribute('innerHTML'))["ou"]
img = json.loads(x.get_attribute('innerHTML'))["ou"]
imgtype = json.loads(x.get_attribute('innerHTML'))["ity"]
try:
req = urllib2.Request(img, headers={'User-Agent': header})
raw_img = urllib2.urlopen(req).read()
File = open(os.path.join(searchterm , searchterm + "_" + str(counter) + "." + imgtype), "wb")
File.write(raw_img)
File.close()
succounter = succounter + 1
except:
print "can't get img"
print succounter, "pictures succesfully downloaded"
browser.close()
위의 코드는 python 를 통해 구글 이미지를 크롤링하는 코드입니다.
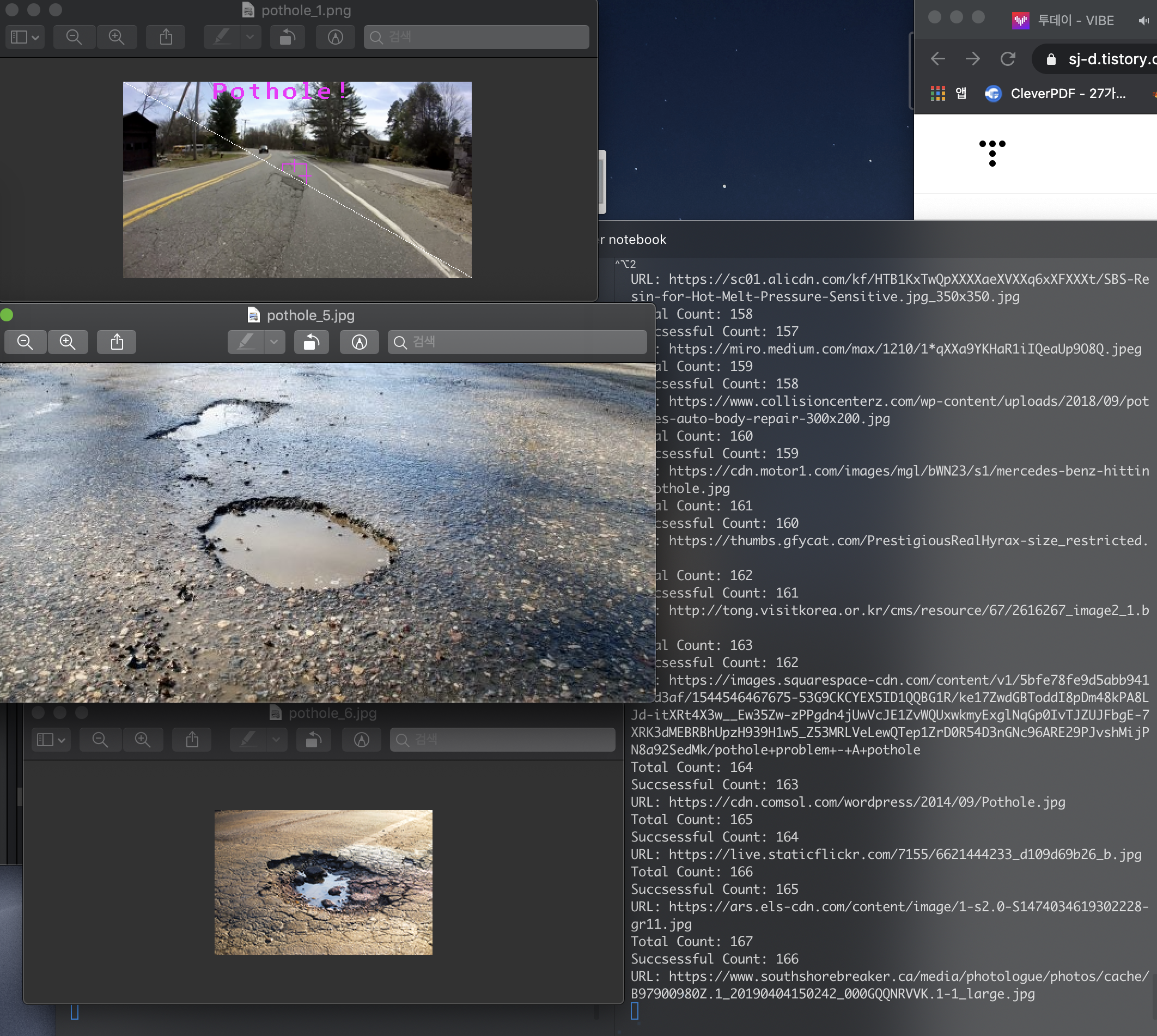
다음과 같이 이미지가 다운로드 되어집니다.
2. Google Images Download 라는 python 스크립트를 github에서 가져와 사용하기
자신이 작업을 원하는 디렉토리로 이동하여 다음의 명령어를 입력해줍니다.
$ git clone https://github.com/hardikvasa/google-images-download.git
$ cd google-images-download && sudo python setup.py install
다음 명령어를 입력해준다음 다음의 옵션들을 통하여 google images download라는 스크립트를 실행할수있습니다.

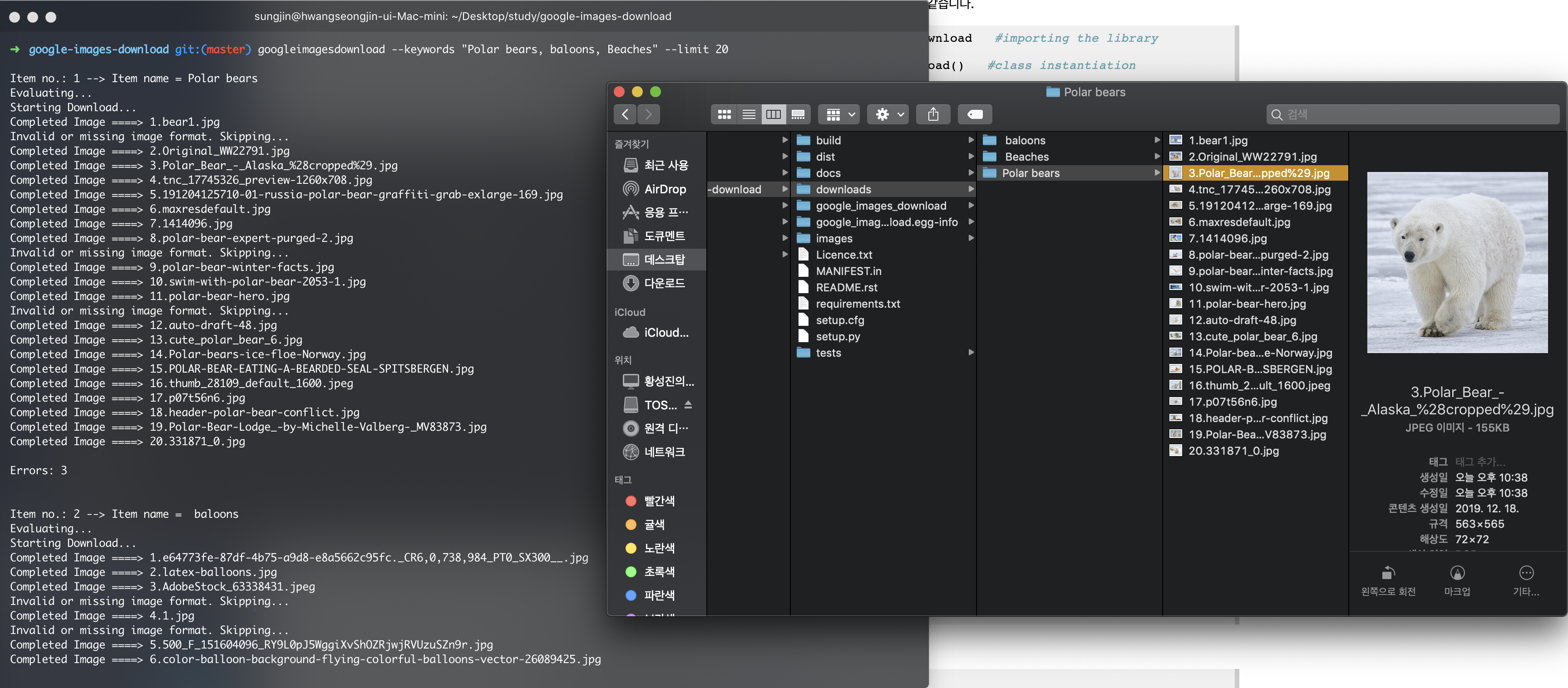
이렇게 이미지를 다운로드하게 되면 다음과 같은 google-images-download의 디렉토리 내의 downloads 라는 디렉토리에 다운로드가 됩니다.
참고
① 이미지 크롤링
① 이미지 크롤링 (Image Crawling) Google 이미지에서 거미(spider)이미지를 가져옵니다. Google 이미지는 페이지 스크롤 없이 최대 100개만 가져옵니다. 하지만 Selenium을 사용하면 더 많은 이미지를 가져올 수..
jeongmin-lee.tistory.com